
Bloom Filter的算法
在Bloom Filter 中使用位数组来辅助实现检测判断。在初始状态下,我们声明一个包含m位的位数组,它的所有位都是0,如图14-7所示。
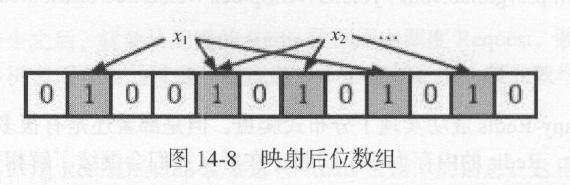
现在我们有了一个待检测集合,其表示为S={x1, h ,…, Xn } 。接下来需要做的就是检测一个x是否已经存在于集合S中。在Bloom Filter 算法中,首先使用k个相互独立、随机的散列函数来将集合S中的每个元素X1,X2,…Xn,映射到长度为m的位数组上,散列函数得到的结果记作位置索引,然后将位数组该位置索引的位置l 。例如,我们取k为3,表示有三个散列函数,x1经过三个散列函数映射得到的结果分别为l 、4 、8, X2 经过三个散列函数映射得到的结果分别为4 、6 、10 ,那么位数组的1、4、6、8、10。这五位就会置为1,如图14-8所示。
如果有一个新的元素x,我们要判断x是否属于S集合,我们仍然用k个散列函数对x求映射结果。如果所有结果对应的位数组位置均为l,那么x属于S这个集合,如果有一个不为1,则x不属于S集合。
例如,新元素x 经过三个散列函数映射的结果为4、6、8,对应的位置均为1,则x属于S集合。如果结果为4、6、7,而7对应的位置为0,则x不属于S集合。
注意,这里m、n、k满足的关系是m>nk时,也就是说位数组的长度m要比集合元素n和散列函数k的乘积还要大。
这样的判定方法很高效,但是也是有代价的,它可能把不属于这个集合的元素误认为属于这个集合。
当k值确定时,随着m/n的增大,误判概率逐渐变小。当m/n的值确定时,当k越靠近最优K值,误判概率越小。(计算公式不展示)
代码
1 | class HashMap(object): |
value 是要被处理的内容。这里遍历了value的每一位,并利用ord( )方法取到每一位的ASCII码值,然后混淆seed进行迭代求和运算,最终得到一个数值。这个数值的结果就由value和seed唯一确定。再将这个数值和m进行按位与运算,即可获取到m位数组的映射结果,这样就实现了一个由字符串和seed来确定的散列函数。当m固定时,只要seed值相同,散列函数就是相同的,相同value必然会映射到相同的位置。所以如果想要构造几个不同的散列函数,只需要改变其seed就好了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# seed取值范围
BLOOMFILTER_HASH_NUMBER = 6
# 需要的位数m
BLOOMFILTER_BIT = 5
class BloomFilter(object):
"""
Bloom Filter 里面需要用到k个散列函数,这里要对这几个散列
函数指定相同的m值和不同的seed值
"""
def __init__(self, server):
self.block_num = 1,
self.key = 'BloomFilter'
self.m = 1 << BLOOMFILTER_BIT
self.seeds = range(BLOOMFILTER_HASH_NUMBER)
self.server = server
# 散列函数列表
self.maps = [HashMap(self.m, seed) for seed in self.seeds]
def exists(self, value):
# 判断元素是否重复
if not value:
return False
exist = 1
for map in self.maps:
offset = map.hash(value)
exist = exist & self.server.getbit(self.key, offset)
return exist
def insert(self, value):
for f in self.maps:
offset = f.hash(value)
print(offset)
self.server.setbit(self.key, offset, 1)
传入散列函数的个数,用它来生成几个不同的seed。用不同的seed来定义不同的散列原函数,这样我们就可以构造一个散列函数列表。遍历seed,构造带有不同seed值的HashMap对象,然后将HashMap对象保存成变量maps供后续使用。另外,server就是Redis连接对象,key就是这个m位数组的名称。